
Open Source Dependencies 🔗
I find it very interesting how comfortable we, software engineers, have become with the notion of including thousands, and thousands, of lines of code we know nothing about in our projects. I don’t think reusing open-source libraries is bad. Quite the opposite; I am convinced that software development based on open-source software (OSS) is what allows us to move ahead in the industry at a fast pace.
However, we seem to have put a sort of blind faith in the OSS libraries and other tools we use every day. Somehow, it is accepted, without hesitation, that for the 100 lines of code that I need to process the data from a couple of Html forms, I have to include eighty thousand more lines from nodejs libraries (e.g. from NestJS dependencies) I know very little about. The technical term for this development mechanism is “Open-Source Software Supply Chain”.
When considered, the challenge of managing the OSS supply chain is not trivial: how can I guarantee that those 80,000 lines of code I included in my project are not only correct, and performant, but also safe? The challenge becomes even larger when we consider that some of those OS libraries are constantly evolving and others are completely abandoned by their creators. As these projects evolve or become obsolete, new weaknesses arise from incompatibilities, obsolescence, and the work of the ever-curious hacking community.
Abandonware 🔗
The risks that we take, whether we want it or not, by reusing OSS code are numerous. Ladisa, Plate, et al., identified 107 unique OSS supply chain attack vectors related to 94 real security incidents [1]. But let’s not get overwhelmed and focus on one particular challenge: obsolete or abandoned projects.
As it is inevitable, the community already assigned a corresponding jargon to this: “abandonware”. Wikipedia defines abandonware as a product, typically software, ignored by its owner and manufacturer, and for which no official support is available. An abandoned or “slow” project is not necessarily a vulnerability in itself -after all, there are legitimate reasons for not modifying a library for a long time- however, it does increase the risk of inheriting problems or inefficiencies over time.
Source Code Scanning 🔗
The first line of defense against OSS supply chain attacks is the Static Analysis of the project’s source code and its dependencies. There are very good tools in the market -both free and commercial- to scan the project’s code and find potential problems. A list of these tools can be found here https://owasp.org/www-community/Source_Code_Analysis_Tools
The Typical OSS Scanner works like this:
- Creates a “Bill Of Materials” or inventory of the software artifacts that compose the project.
- Searches the known vulnerabilities databases (CVE) for entries about the SW artifacts and specific versions found in the project.
- Additionally, verifies the licensing information to prevent the breach of policies or intellectual property infringement.
But what about the project’s health? 🔗
The state of the dependencies maintenance -commonly known as project health- is often not considered. This is especially the case for the free or community versions of these tools. It is surprisingly easy, however, to get good information about the health of OSS libraries from code repositories like GitHub.
Evaluating the health of the OSS supply chain: an example 🔗
Let us consider a simple Golang program I wrote earlier this year.
The project dependencies are listed in the go.mod file. We must also consider that each one of these dependencies is a project with its own dependencies.
module github.com/carlosolmos/myproject
go 1.16
require (
github.com/armon/consul-api v0.0.0-20180202201655-eb2c6b5be1b6 // indirect
github.com/coreos/etcd v3.3.10+incompatible // indirect
github.com/coreos/go-etcd v2.0.0+incompatible // indirect
github.com/go-sql-driver/mysql v1.6.0 // indirect
github.com/google/uuid v1.3.0
github.com/gorilla/mux v1.8.0
github.com/sirupsen/logrus v1.8.1
github.com/spf13/viper v1.9.0 // indirect
github.com/stretchr/testify v1.7.0
github.com/ugorji/go/codec v0.0.0-20181204163529-d75b2dcb6bc8 // indirect
github.com/xordataexchange/crypt v0.0.3-0.20170626215501-b2862e3d0a77 // indirect
golang.org/x/text v0.3.7
)
What I want is to be able to:
- Scan the OSS dependencies that are included in my projects, recursively.
- Give me a sense (maybe a score) of the health of every library based on its activity.
BOM 🔗
First, we get a more complete list of dependencies (the Bill of Materials or BOM) for this project.
~/lab/go/src/github.com/carlosolmos/myproject
❯ go list -json -deps > myproject-dependencies.txt
This command creates a deeper list of dependencies (the file has over 17,000 lines) for every OSS artifact referenced in the project. Here is the file I got for my project.
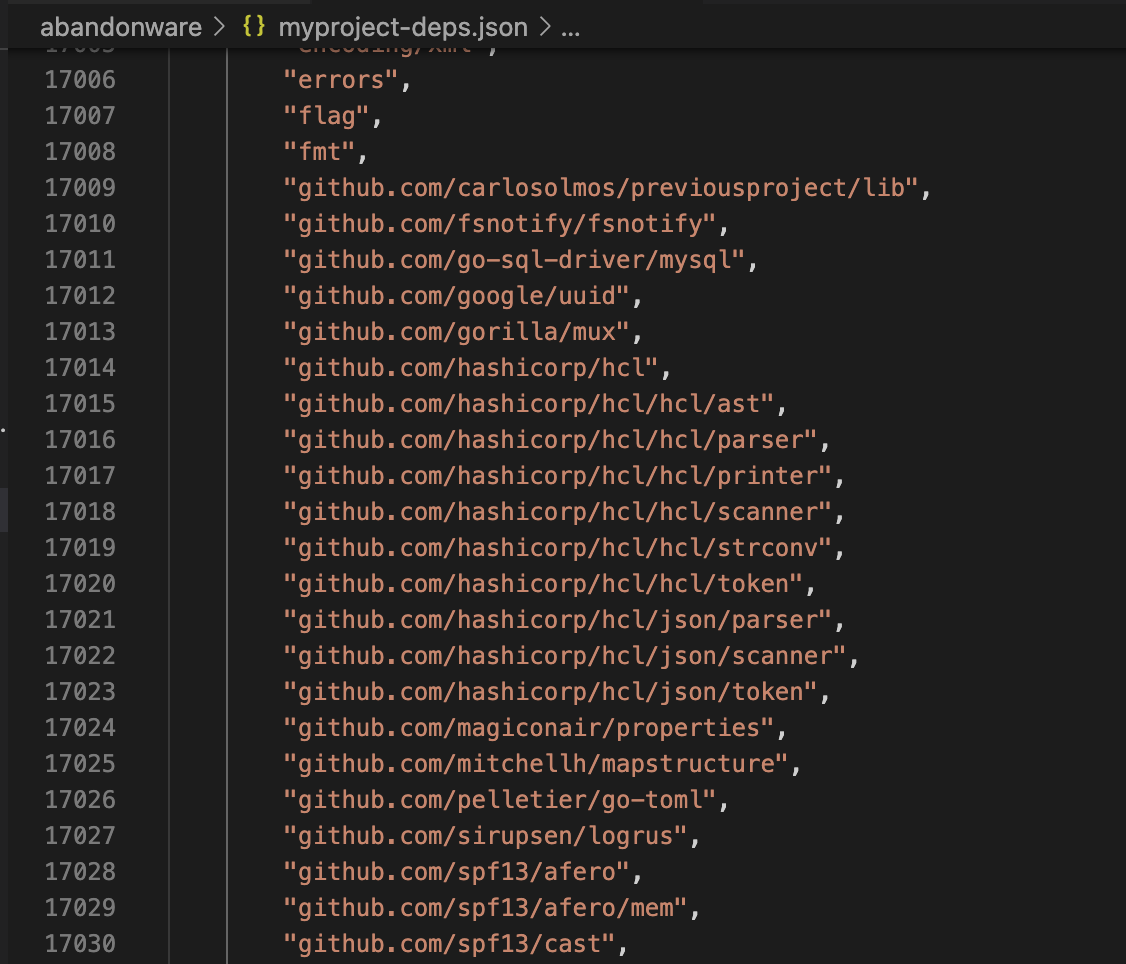 click to zoom in
click to zoom in
GitHub API 🔗
GitHub offers rich information about the activity of every public repository. We can review how many people participate, when was the last push of code, how many lines of code have been added or deleted, or how many commits has a project had on a particular week —the Mastodon people have been busy lately, I wonder why 😛
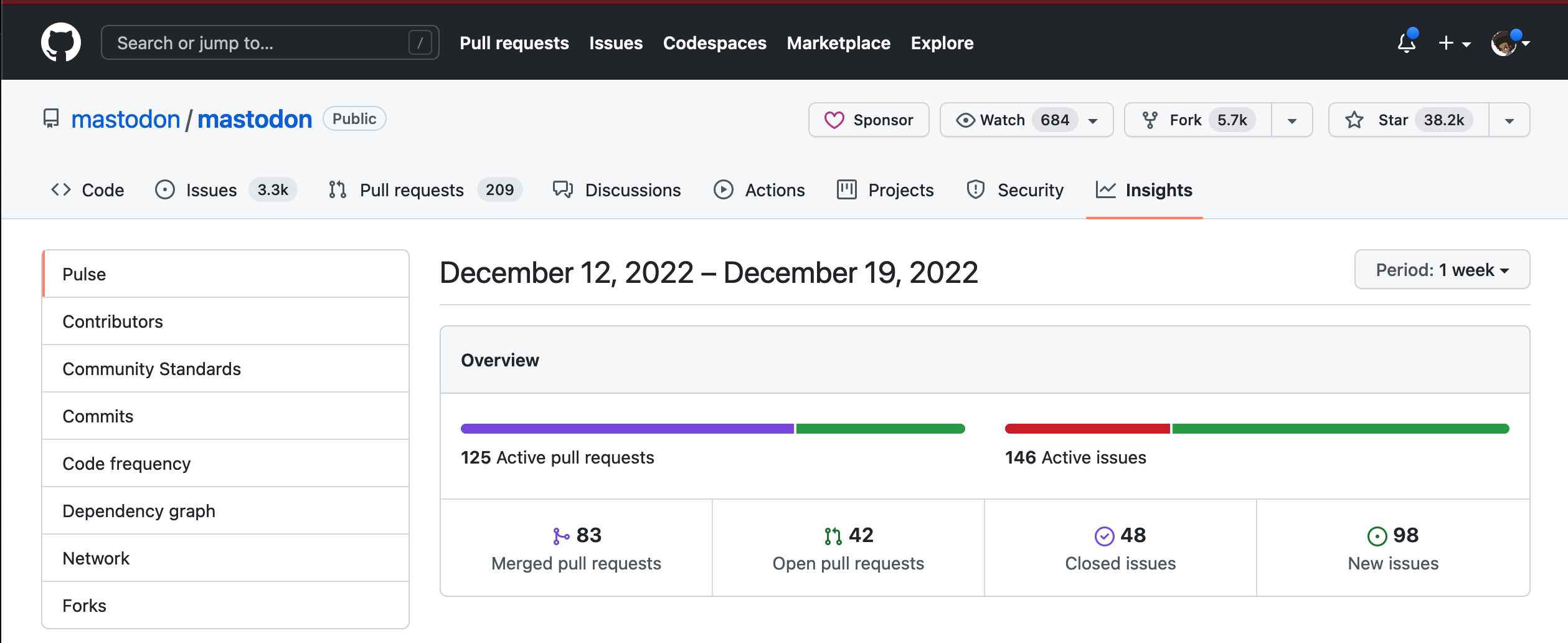 click to zoom in
click to zoom in
 click to zoom in
click to zoom in
This trove of activity information is also available via the GitHub API. The Repository Statistics API provides endpoints for the different categories of data. And we can use it for free!
I am interested in two endpoints:
The repository description:
https://api.github.com/repos/OWNER/REPOSITORY"
and the repository weekly commit count:
"https://api.github.com/repos/OWNER/REPOSITORY/stats/participation"
I plan to evaluate the health of the project based on its count of recent activity.
The Personal Token 🔗
The one thing I need to use the GitHub public API is an Access Token, particularly a Personal Access Token (classic) with enough privileges to access public repositories and to read the project information (there is no need for any write privileges, keep the scope short). The guide to creating one of these tokens can be found in the official documentation.
 click to zoom in
click to zoom in
Note: I found the panel for creating the tokens inside the “Developer Settings” menu. This is not mentioned in the guide.
The Scanner 🔗
Now that I have my token and the endpoints that I need, I can create a small script to parse the GitHub repositories from my project’s BOM and assess the health of each dependency. I am using Python for this, but it can be done in any language.
Warning! This code is ugly, and messy, and should not be used in production. Treat it as toxic. 💀
The general idea of the program is simple: read each line of the BOM file and extract the GitHub URLs. Retrieve and parse the GitHub information for the repository, and keep it in a dictionary to avoid duplication (we want to query each repo only once). Finally, print the parsed information to the standard output.
report={}
file1 = open('myproject-deps.json', 'r')
lines = file1.readlines()
for line in lines:
line = clean(line)
if line.find("github.com") == 0:
print("Repo: {}".format(line))
toks=line.split("/")
if len(toks) > 2:
owner = toks[1]
project = toks[2]
key = "github.com/{}/{}".format(owner, project)
if key not in report:
info = getGithubInfo(owner, project)
if info:
print(info)
report[key]=info['score']
time.sleep(0.5)
Notice the pause between API calls. This is just me being civilized and avoiding rate limits from the GitHub servers.
The interesting part of the script is the function getGithubInfo(owner, project) where I fetch and extract the information that I want. The function makes two API calls. The first is to retrieve the repository general information.
response = requests.get(
"https://api.github.com/repos/{}/{}".format(owner, project),
headers={'Accept': 'application/vnd.github+json',
'Authorization':"Bearer {}".format(TOKEN),
'X-GitHub-Api-Version': '2022-11-28'},
)
if(response.status_code != 200):
return None
json_response = response.json()
info['url'] = json_response['url']
info['full_name'] = json_response['full_name']
info['created_at'] = json_response['created_at']
info['last_push'] = json_response['pushed_at']
The second call is to retrieve the weekly commit count. The API returns the count for the last 52 weeks. I care about the recent history so I do some aggregation for the last 4, 12, and 24 weeks, and the grand total for the year.
response = requests.get(
"https://api.github.com/repos/{}/{}/stats/participation".format(owner, project),
headers={'Accept': 'application/vnd.github+json',
'Authorization':"Bearer {}".format(TOKEN),
'X-GitHub-Api-Version': '2022-11-28'},
)
if(response.status_code != 200):
return None
info['last_year_commit_count'] = 0
info['last_24_weeks_commit_count'] = 0
info['last_12_weeks_commit_count'] = 0
info['last_4_weeks_commit_count'] = 0
json_response = response.json()
allContribs = json_response['all']
if allContribs and len(allContribs) == 52:
for i in range(52):
week = allContribs[51-i]
info['last_year_commit_count'] += week
if i<24:
info['last_24_weeks_commit_count'] += week
if i<12:
info['last_12_weeks_commit_count'] += week
if i<4:
info['last_4_weeks_commit_count'] += week
Finally, I want to calculate a score based on the activity frequency. I came up with a very lazy algorithm, but it gives me an idea of how active the project is. I am positive that there are much better ways to calculate this score.
"""
Every commit in a year = 1 pts
Every commit in the last 6 months +1pts
Every commit in the last 12 weeks +10pts
Every commit in the last 4 weeks +100 pts
"""
info['score'] = (info['last_year_commit_count']) + \
(info['last_24_weeks_commit_count']) + \
(info['last_12_weeks_commit_count']*10) + \
(info['last_4_weeks_commit_count']*100)
The entire code can be found here: https://github.com/carlosolmos/blogresources
When I run the script against the BOM of my project, I get this report:
==REPOSITORIES REPORT==
github.com/stretchr/testify 52
github.com/sirupsen/logrus 10
github.com/magiconair/properties 1025
github.com/spf13/afero 49
github.com/spf13/pflag 0
github.com/hashicorp/hcl 270
github.com/davecgh/go-spew 0
github.com/pelletier/go-toml 246
github.com/subosito/gotenv 14
github.com/fsnotify/fsnotify 609
github.com/mitchellh/mapstructure 36
github.com/spf13/cast 4
github.com/spf13/jwalterweatherman 0
github.com/spf13/viper 446
github.com/go-sql-driver/mysql 383
github.com/gorilla/mux 227
github.com/google/uuid 0
Analyzing the score 🔗
My cheap lazy formula returns some interesting results. I found a few libraries that make me a little nervous because they haven’t been active in a long time. Maybe that is okay. Maybe there is nothing more to do there but still is worth investigating.
First, let’s review github.com/google/uuid. A library to create UUIDs. According to the report, the repo hasn’t had commits all year.
The GitHub page marks the last commit in July, 2021.
 click to zoom in
click to zoom in
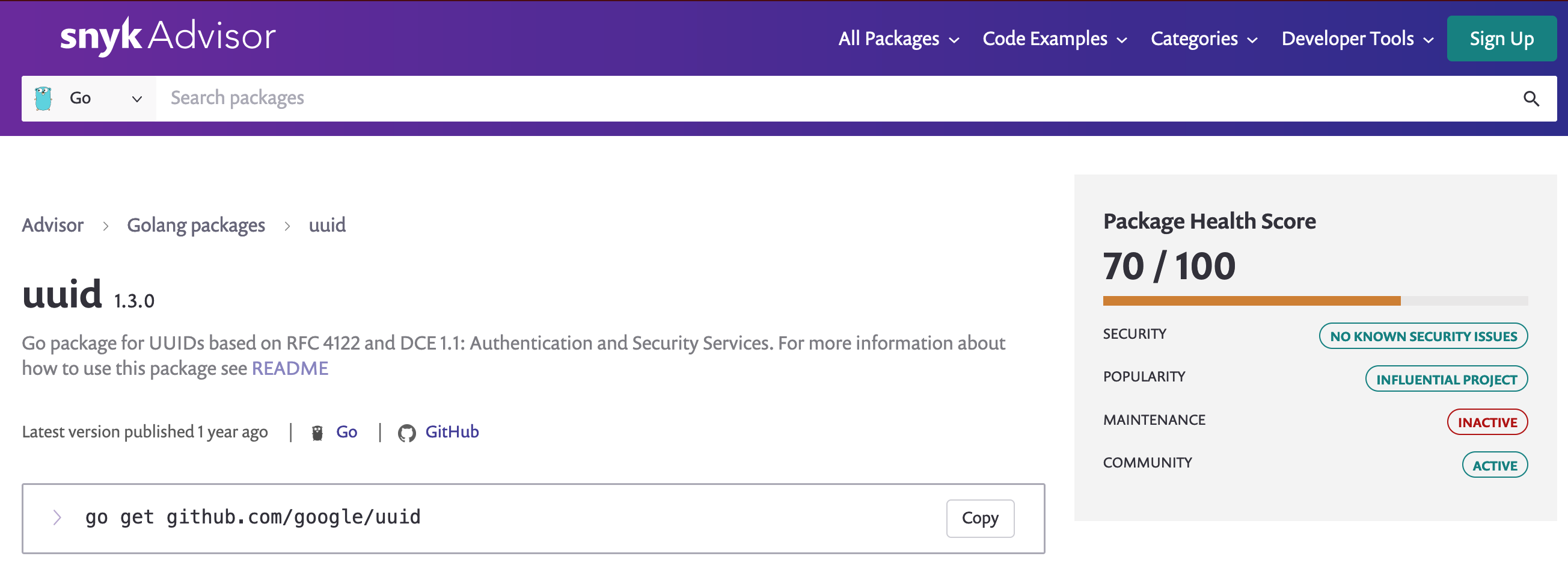
The Snyk Advisor — a popular code scanning security tool- has a profile for the package with a score of 70/100.
 click to zoom in
click to zoom in
This is a very popular Go library created by Google (over 4,000 stars on GitHub, and included in over 24,000 projects at this time). There are no known vulnerabilities in the CVE databases at this time. I suppose we can give it the benefit of the doubt.
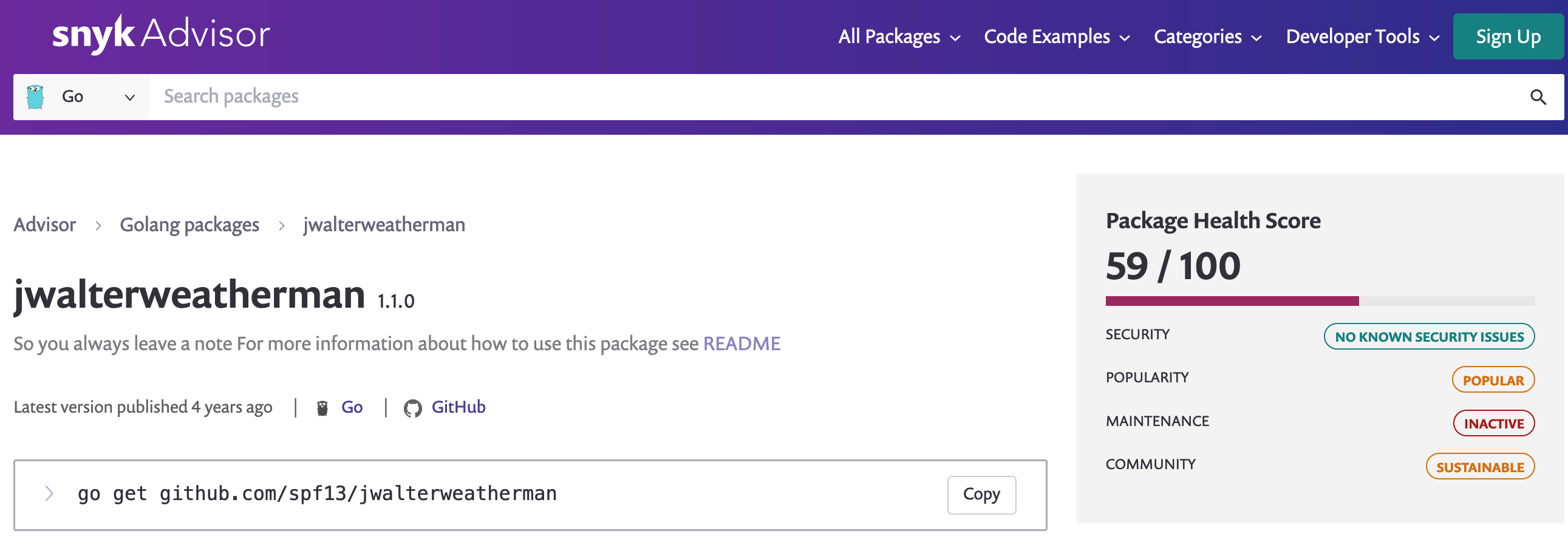
Now let’s review github.com/spf13/jwalterweatherman. I did not include this library myself. It is included in one of the libraries I use in my program. The GitHub page explains its purpose as “Seamless printing to the terminal (stdout) and logging to a io.Writer (file) that’s as easy to use as fmt.Println."
The last commit was 2 years ago, but most files haven’t been touched in over 4 years. The last release was created in 2019.
 click to zoom in
click to zoom in
Its Snyk score is 59/100 due to its lower popularity. However, there a no known vulnerabilities at this time.
 click to zoom in
click to zoom in
Maybe it is time I find myself another configuration library for my project. —But I love viper so much! 🐍
Just consider it 🔗
In this document, I am not looking to discredit any library nor provide an axiom about the relation between an OSS project activity and its level of risk. Like I said before, my formula is weak. What I want is to encourage you, dear reader, to consider the quality of the code that you may be inadvertently inserted in your code base, and to show you that the information to evaluate said code is readily available.
I leave the formula up to you.
More information 🔗
[1] “Taxonomy of Attacks on Open-Source Software Supply Chains”, Piergiorgio Ladisa, Henrik Plate, Matias Martinez, and Olivier Barais. https://arxiv.org/abs/2204.04008. In this paper, the authors identify 107 unique attack vectors related to 94 real security incidents. I recommend the reading because they also propose a series of safeguards against those attacks. It is worth the time.
[2] A good recent article on this subject: “OSS Supply What Will It Take?. A discussion with Maya Kaczorowski, Falcon Momot, George Neville-Neil, and Chris McCubbin”.2022, November 16.ACM Queue. https://queue.acm.org/detail.cfm?id=3570923.
[3] A good blog post from Sonatype recognizes the challenge of the OSS supply chain: https://blog.sonatype.com/manage-and-eliminate-technical-debt
[4] “Software Supply Chain Map: How Reuse Networks Expand”, Hideaki Hata, Takashi Ishio. https://arxiv.org/abs/2204.06531.